Nemrégiben rábukkantunk egy rendkívül informatív blogbejegyzésre a Composio Dev oldalán, amely három vezető mesterséges intelligencia-modellt vetett alá részletes összehasonlításnak a kódolás teljesítményük alapján. Bár nem mi végeztük ezeket a teszteket, az eredmények tanulságosak, és úgy gondoltuk, fontos, hogy ti is megismerkedjetek velük. Ebben a blogban összegyűjtöttük az ott olvasott információk lényegét, hogy egy kényelmes összefoglalót nyújthassunk.
A három bemutatott modell az Anthropic által fejlesztett Claude Opus 4, a Google DeepMind által támogatott Gemini 2.5 Pro és az OpenAI legújabb fejlesztése, az o3. A tesztek alapján magasan kiemelkedett egy modell, de a többiek eredményei is izgalmas betekintést nyújtottak a jelenlegi mesterséges intelligencia-fejlesztésekbe.
Összefoglalva
A Composio Dev blog alapján a Claude Opus 4 bizonyult a legjobbnak mind a teszteredmények, mind a gyakorlati hatékonyság szempontjából. Míg az OpenAI o3 és a Gemini 2.5 Pro szintén figyelemreméltó teljesítményt nyújtott, az Opus 4 minden vizsgált területen megelőzte őket. Ez a modell nemcsak magas benchmark pontszámokat ért el, hanem összetett kódolási problémákat is lenyűgözően oldott meg.
Most nézzük meg alaposabban a három modell jellemzőit és teszteken nyújtott teljesítményét!
Claude Opus 4 rövid bemutatása
A blog szerzője kifejezetten dicsérte az Anthropic által fejlesztett Claude Opus 4 modellt, amely 2025 májusában jelent meg. Ez az AI platform célzottan a kódolási feladatok optimalizálására készült, és már most a legjobbak közé sorolható az iparágban.
Technikai jellemzők
- Kontextusablak: Kb. 200 000 token, amely lehetővé teszi hosszabb kódblokkok feldolgozását.
- SWE benchmark: 72,5%-os pontszám, ami a párhuzamos számítás használatával akár 79,4%-ra is növelhető. Ez jóval meghaladja az előző Anthropic-modell, a Claude 3.7 Sonnet teljesítményét.
- Hatékonyság: Az Opus 4 akár egy teljes vállalati munkanapon keresztül képes autonóm módon feladatokat végrehajtani, ami példátlan fejlesztési eszközzé teszi.
- Pontosság: Jelentősen csökkenti a „hacky” megoldások használatát, minimalizálva az ad hoc jellegű programozási hibákat.
Nézzük meg, hogyan teljesített a gyakorlati tesztek során!
Kódolási teljesítmény összehasonlítása
A blog négy különböző kódolási feladat alapján vetette össze a modelleket. Ezek a tesztek azt a célt szolgálták, hogy megmutassák az AI modellek valódi képességeit a gyakorlatban.
1. Partikulák morfolásának megvalósítása
Feladat
Olyan animációt kellett létrehozni, amelyben partikulumok egyik formából a másikba „morfálódnak” vizuálisan.
Eredmények
Claude Opus 4:
A modell kevesebb, mint két perc alatt generált egy kifogástalan animációt, ahol a partikulumok fokozatosan, zökkenőmentesen alakultak át. Bár néhány alakzat nem volt teljesen pontos, az interpretáció és a technikai kivitelezés kiváló volt.
Gemini 2.5 Pro:
A generált animáció működött, de pontosság és vizuális részletek terén elmaradt az Opus 4-től. Az alakzatok kevésbé voltak tisztán felismerhetők.
OpenAI o3:
Sajnos ez a modell gyenge teljesítményt nyújtott. Az animációi előbb egy alapértelmezett gömbalakra váltottak, mielőtt az új alakot felvették volna, ami jelentősen rontotta az élményt.
2. 2D Mario játék fejlesztése
Feladat
Egy egyszerű Mario játékot kellett létrehozni Vanilla JavaScript segítségével.
Eredmények
Claude Opus 4:
A generált játék nemcsak működött, hanem vizuálisan is lenyűgöző volt. A blog szerző kiemelte, hogy ez a kód akár alapként is szolgálhat azok számára, akik Mario játékot szeretnének fejleszteni.
Gemini 2.5 Pro:
A játék működőképes volt, de hibákat tartalmazott, például az időzítő nem működött megfelelően.
OpenAI o3:
Az o3 nem tudta teljesíteni a feladatot. Az elkészült játék inkább egy vázlatos prototípus volt, tele hibákkal.
3. Tetris játék megvalósítása
Feladat
Egy klasszikus Tetris játék implementálása, többek között a darabok előrejelzésével és magas pontszámok mentésével.
Eredmények
Claude Opus 4:
Az Opus 4 minden elvárást túlteljesített. Minden kért funkciót implementált, sőt, további extrákat is hozzáadott, például háttérzenét.
Gemini 2.5 Pro:
A játék működött, de hiányoztak az Opus 4 által kínált plusz funkciók és vizuális részletek.
OpenAI o3:
Az o3 működőképessé tette a játékot, de sok fontos funkció hiányzott, például a téglák elérésekor hiányzott a „game over” logika.
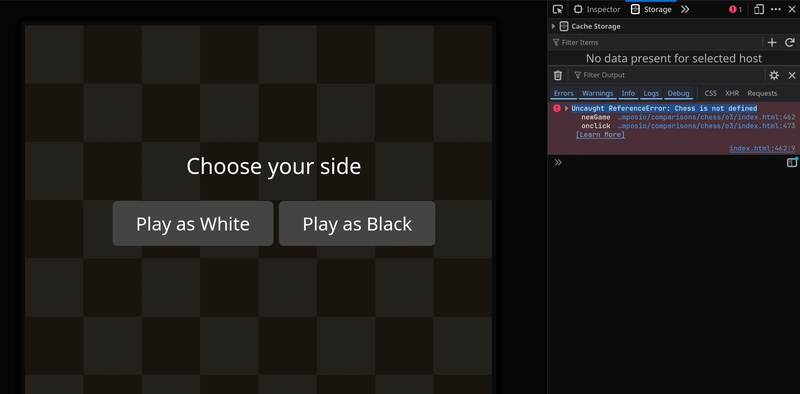
4. Sakk játék fejlesztése
Feladat
Egy teljesen működő sakkjátékot kellett létrehozni alapvető szabályokkal.
Eredmények
Claude Opus 4:
Az Opus 4 egy működő sakkjátékot generált, amely megbirkózott minden alapvető szabállyal. Bár néhány speciális lépés nem volt implementálva (mint az „en passant”), az alapok lenyűgöztek.
Gemini 2.5 Pro:
A modell elkészítette a sakkjátékot, de a logikája gyakran hibás volt.
OpenAI o3:
Az o3 a Chess.js könyvtárra támaszkodott, de a megvalósítás hibás volt, így a játék nem működött megfelelően.
Miért emelkedik ki a Claude Opus 4?
Az Anthropic modellje nemcsak technikai jellemzőiben tűnt ki, hanem a gyakorlatban is bizonyította képességeit. A Composio Dev blog szerzője szerint az Opus 4 stabilitása, sebessége és pontossága egyaránt lenyűgöző. Legyen szó kreatív feladatokról, mint az animáció, vagy komplex programozási kihívásokról, mint a játékfejlesztés, az Opus 4 mindig előnyben volt.
Záró gondolatok
A Claude Opus 4 egyértelműen új szintet képvisel az AI-alapú kódolási megoldások terén. Bár a Gemini 2.5 Pro és az OpenAI o3 szintén kiváló modellek, az Opus 4 különleges teljesítménye kiemelkedett. Ha kíváncsi vagy a részletekre, látogass el az eredeti blogbejegyzésre a Composio Dev oldalán.
Te mit gondolsz? Melyik modellt próbálnád ki először?